



zkML:通过零知识密码学让智能合约更聪明
MarsBit热度: 22929
虽然 zkML 仍处于早期发展阶段,但它已经开始显示出令人鼓舞的结果。随着技术的发展和成熟,我们可以期待看到 zkML 在链上的更多创新使用案例。
原文标题:zkML: Evolving the Intelligence of Smart Contracts Through Zero-Knowledge Cryptography
原文作者:Accelxr,1kx
原文来源:Mirror
编译:Lynn,MarsBit
**通过 zkSNARK 证明机器学习(ML)模型推理,有望成为这十年来智能合约领域最重要的进展之一。**
这一发展开辟了一个令人振奋的巨大设计空间,使应用程序和基础设施发展成为更复杂的智能系统。
通过添加 ML 功能,智能合约可以变得更加自主和动态,使其能够根据链上的实时数据做出决定,而不仅仅是静态规则。智能合约将是灵活的,可以适应各种场景,包括最初创建合约时可能没有预料到的场景。简而言之,ML 的能力将扩大我们放在链上的任何智能合约的自动化、准确性、效率和灵活性。
在许多方面,鉴于 ML 在 Web3 以外的大多数应用中的突出地位,智能合约今天没有使用嵌入式 ML 模型是令人惊讶的。 这种没有 ML 的情况主要是由于在链上运行这些模型的高计算成本。例如,FastBERT,一个计算优化的语言模型,使用 ~1800 MFLOPS(百万浮点运算),直接在 EVM 上运行是不可行的。
当考虑在链上应用 ML 模型时,主要重点是推理阶段:应用模型对真实世界的数据进行预测。为了拥有 ML 规模的智能合约,合约必须能够摄取这样的预测,但正如我们前面提到的,直接在 EVM 上运行模型是不可行的。zkSNARK 给了我们一个解决方案:任何人都可以在链外运行一个模型,并产生一个简洁和可验证的证明,显示预期的模型实际上产生了一个特定的结果。这个证明可以在链上发布,并被智能合约摄取,以放大其智能。
在这篇文章中,我们将:
- 回顾链上 ML 的潜在应用和用例
- 探讨新兴项目和基础设施建设在 zkML 中的核心地位
- 讨论现有实施的一些挑战以及 zkML 的未来可能是什么样子的
关于 ML 的快速入门知识
机器学习(ML)是人工智能(AI)的一个子领域,专注于开发算法和统计模型,使计算机能够从数据中学习并做出预测或决策。ML 模型通常有三个主要组成部分:
- 训练数据: 一组输入数据,用于训练机器学习算法,使其对新数据进行预测或分类。训练数据可以有多种形式,如图像、文本、音频、数字数据,或这些数据的组合。
- 2.模型架构: 一个机器学习模型的整体结构或设计。它定义了层的类型和数量,激活函数,以及节点或神经元之间的连接。架构的选择取决于具体问题和使用的数据。
- 模型参数: 模型在训练过程中学习的值或权重,以进行预测。这些值通过优化算法反复调整,使预测结果和实际结果之间的误差最小。
模型的制作和部署分为两个阶段:
- 训练阶段: 在训练过程中,模型被暴露在一个有标签的数据集中,并调整其参数以最小化预测结果和实际结果之间的误差。训练过程通常涉及几个迭代或 epochs,模型的准确性在一个单独的验证集上进行评估。
- 推理阶段: 推理阶段是指训练好的机器学习模型被用来对新的、未见过的数据进行预测。该模型接受输入数据,并应用所学的参数来生成输出,如分类或回归预测。
zkML 今天主要集中在 ML 模型的推理阶段,而不是训练阶段,主要是由于在线验证训练的计算复杂性。不过,zkML 对验证推理的关注并不是一种限制:我们期望推理阶段能产生一些非常有趣的用例和应用。
验证过的推理情景
核实推理有四种可能的情况:
- **私人输入,公共模型。**模型消费者(MC)可能希望对模型提供者(MP)的输入保持隐私。例如,一个 MC 可能希望向贷款人证明一个信用评分模型的结果,而不透露他们的个人财务信息。这可以通过使用预先承诺计划和在本地运行模型来实现。
- 公共输入,私人模型。 ML 即服务的一个常见问题是,MP 可能希望隐藏他们的参数或权重以保护他们的知识产权,而 MC 希望验证生成的推论确实来自于对抗性环境中的指定模型。这样想吧:当向 MC 提供推论时,MP 有动机运行一个较轻的模型以节省成本。使用链上的模型权重承诺,MC 可以在任何时候审计一个私有模型。
- **私人输入,私人模型。**当用于推理的数据是高度敏感或保密的,并且模型本身被隐藏以保护知识产权时,就会出现这种情况。这方面的一个例子可能包括使用私人病人信息对医疗模型进行审计。zk 中的组合技术或使用多方计算(MPC)或 FHE 的变体可用于服务这种情况。
- **公共输入,公共模型。**当模型的所有方面都可以是公共的,zkML 解决了一个不同的用例:压缩和验证链外计算到链上环境。对于较大的模型,验证一个简洁的推理的 zk 证明比自己重新运行模型更有成本效益。
应用和机会
经过验证的 ML 推理为智能合约开辟了一个新的设计空间。一些加密货币的原生应用包括:
DeFi
- **可验证的链外 ML 预言机。**继续采用生成式人工智能可能有助于推动行业为其内容实施签名计划(例如,新闻出版物签署文章或图片)。签名的数据是 ZK 预备的,并使数据可组合和可信。ML 模型可以在链外处理这些签名数据,以进行预测和分类(例如,对选举或天气事件的结果进行分类)。这些链外的 ML 预言机可用于无信任地解决现实世界的预测市场、保险协议合同,以及更多通过验证推理和在链上发布证明。
- ML参数化的DeFi应用。 DeFi 的许多方面可以更加自动化。例如,借贷协议可以使用 ML 模型来实时更新参数。今天,借贷协议主要信任由组织运行的链外模型,以确定抵押品系数、LTV、清算阈值等,但更好的选择是社区训练的开源模型,可以由任何人运行和验证。
- **自动交易策略。**展示金融模型策略回报情况的一个常见方式是由 MP 向投资者提供各种回测。然而,在执行交易时,没有办法验证策略师是否遵循该模型——相反,投资者必须相信策略师确实遵循了该模型。这可能对 DeFi 管理的金库特别有用。
安全
- **智能合约的欺诈监测。**与其让缓慢的人类治理或中心化的行为者控制暂停合约的能力,不如用 ML 模型来检测可能的恶意行为并实施暂停。
传统的 ML
- 可以创建一个协议或市场,允许主持人或其他感兴趣的人验证模型的准确性,而不需要 MP 披露模型的权重。这对于销售模型、围绕模型精度开展竞赛等都很有用。
- **生成性人工智能的非中心化提示市场。**生成性人工智能的提示创建已经发展成为一种复杂的工艺,其中最好的输出生成提示往往是复杂的,有许多修改因素。外部各方可能愿意从创造者那里购买这些复杂的提示。zkML 可以在这里以两种方式使用: 1)验证提示的输出,向潜在的购买者确保提示确实创造了所需的图像,以及2 )允许提示所有者在购买后保持对提示的所有权,对购买者保持模糊,同时仍然为他们生成经过验证的图像。
身份
- **用保护隐私的生物识别认证取代私钥。**私钥管理仍然是 Web3 用户体验中最大的摩擦之一。通过面部识别或其他独特因素抽象出私钥是 zkML 的一个可能的解决方案。
- **公平的空投和贡献者奖励。**一个 ML 模型可以用来创建详细的用户角色,根据多个因素决定空投分配或贡献奖励。当与身份解决方案相结合时,这可能是特别强大的。在这种情况下,一种可能性是让用户运行一个开源模型,评估他们在应用中的参与以及更高层次的参与,如治理论坛帖子,以推断出对他们的分配。然后他们向合同提供这个证明,以获得他们的代币分配。
Web3 社交
- **Web3社交媒体的过滤。**Web3 社交应用的分散性将导致更多的垃圾邮件和恶意内容。理想情况下,社交媒体平台可以使用社区同意的开源 ML 模型,并在选择过滤帖子时公布模型的推理证明。关于这一点,请看 Daniel Kang 对 Twitter 算法的 zkML 分析。
- **广告/推荐。**作为一个社交媒体用户,我可能愿意查看个性化的广告,但希望对广告商保密我的偏好和兴趣。我可以选择在本地运行一个关于我的口味的模型,将其输入媒体应用程序,为我提供内容。在这种情况下,广告商可能愿意为终端用户的这种做法付费,然而这些模型很可能比现在生产的定向广告模型要差得多。
创造者经济/游戏
- **游戏中的经济再平衡。**ML 模型可用于动态调整代币的发行、供应、燃烧、投票阈值等。一个可能的模型是一个激励合约,如果达到一定的再平衡阈值并验证了推理证明,就会对游戏中的经济进行再平衡。
- **新类型的链上游戏。**合作性的人类与人工智能游戏和其他创新的链上游戏可以被创造出来,其中一个不可信任的人工智能模型作为一个 NPC. NPC 的每一个行动都会被发布到链上,并有一个证明,任何人都可以验证,以确定正在运行的模型是正确的。在 Modulus 实验室的 Leela vs. the World 案例中,验证者想要确保所述的 1900 ELO 人工智能正在选择国际象棋的动作,而不是 Magnus Carlson. 另一个例子是 AI Arena,一个任天堂全明星大乱斗风格的 AI 格斗游戏。在高赌注的竞争环境中,玩家希望确保他们训练的模型没有任何干扰或作弊行为。
新兴项目和基础设施
zkML 的生态系统可以大致分为四个主要类别:
- **模型到验证的编译器:**将现有格式的模型(如 Pytorch、ONNX 等)编译成可验证的计算回路的基础设施。
- **通用验证系统:**为验证任意的计算轨迹而建立的验证系统。
- **zkML 专精证明系统:**专门为验证 ML 模型的计算轨迹而建立的验证系统。
- **应用:**从事独特的 zkML 用例的项目。
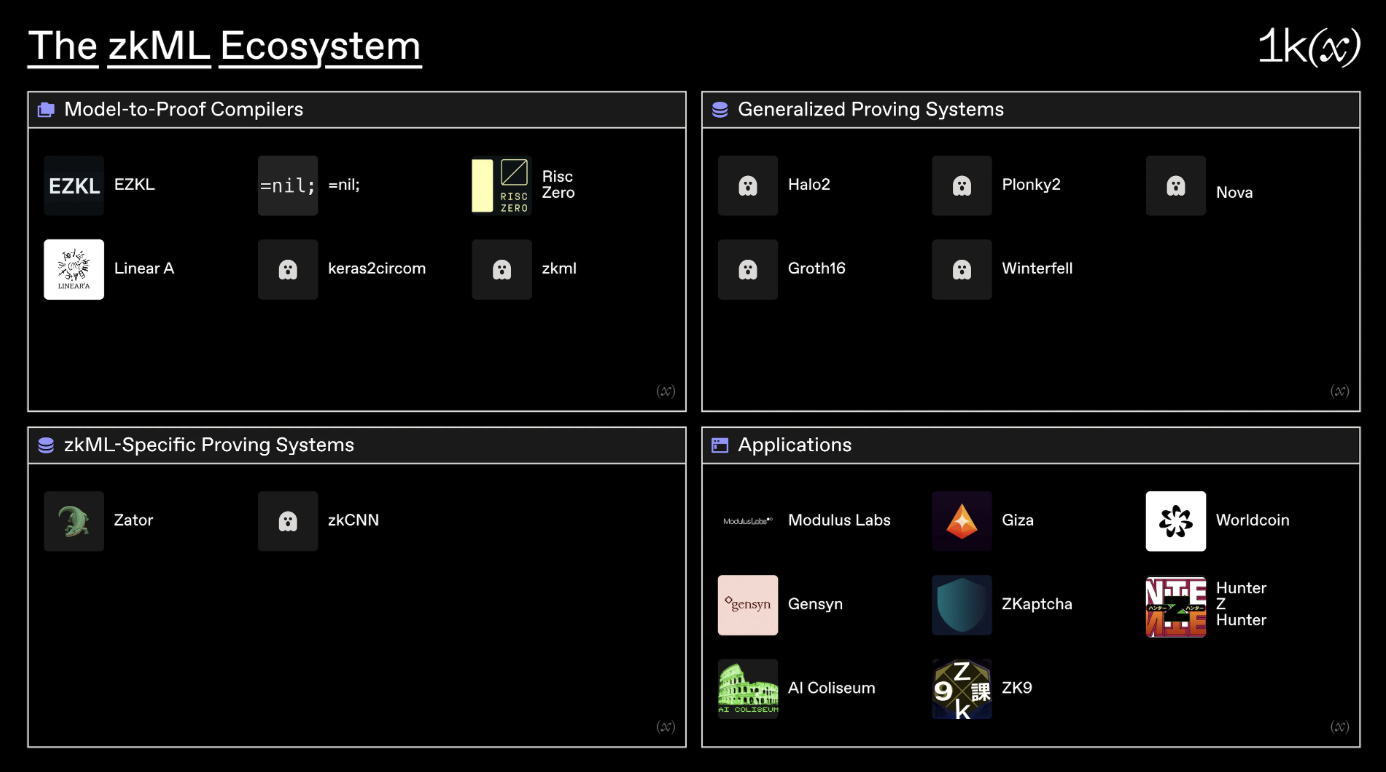
模型到验证的编译器
在考察 zkML 生态系统时,大部分注意力都放在了创建模型到验证的编译器上。一般来说,这些编译器将用 Pytorch、Tensorflow 等编写的高级 ML 模型翻译成 zk 电路。
EZKL 是一个库和命令行工具,用于为 zk-SNARK 中的深度学习模型做推理。通过 EZKL,你可以在 Pytorch 或 TensorFlow 中定义一个计算图,将其导出为 ONNX 文件,并在 JSON 文件中包含一些样本输入,然后将 EZKL 指向这些文件,生成一个 zkSNARK 电路。随着最新一轮的性能改进,EZKL 现在可以在大约 2 秒内证明一个 [MNIST](https://en.wikipedia.org/wiki/MNIST_database#:~:text=The MNIST database (Modified National,the field of machine learning.) 尺寸的模型,并占用 700MB 的 RAM. 迄今为止,EZKL 已经看到了一些重要的早期应用,被用作各种黑客松项目的基础设施。
Cathie So的 circomlib-ml 库含有 Circom 的各种 ML 电路模板。电路包括一些最常见的 ML 函数。 Keras2circom 也是由 Cathie 建立的,它是一个 python 工具,使用底层的 circomlib-ml 库将 Keras 模型转变成 Circom 电路。
LinearA 已经为 zkML 开发了两个框架:Tachikoma 和 Uchikoma. Tachikoma 用于将神经网络转换为纯整数形式并生成计算轨迹。Uchikoma 是一个将 TVM 的中间表示法转换为不支持浮点运算的编程语言的工具。LinearA 计划支持使用场运算的 Circom,以及使用有符号和无符号整数运算的 Solidity.
Daniel Kang 的 zkml 是一个构建 ZK-SNARK 中 ML 模型执行证明的框架,基于他在 Scaling up Trustless DNN Inference with Zero-Knowledge Proofs 论文中的工作。截至本文撰写之时,它能够证明一个 MNIST 电路,使用大约 5GB 的内存和大约 16 秒的运行时间。
关于更普遍的模型到验证的编译器,有 Nil Foundation 和 Risc Zero 两种。Nil Foundation 的 zkLLVM 是一个基于 LLVM 的电路编译器,能够验证用 C++、Rust 和 JavaScript/TypeScript 等流行编程语言编写的计算模型。相对于这里提到的其他一些模型到验证的编译器,它是通用的基础设施,但它仍然适用于像 zkML 这样的复杂计算。当与他们的证明市场相结合时,这可能是特别强大的。
Risc Zero 建立了一个通用的 zkVM 标签,采用开源的 RISC-V 指令集,因此支持现有的成熟语言,如 C++ 和 Rust,以及 LLVM 工具链。这使得主机和客座 zkVM 代码之间可以无缝集成,类似于 Nvidia 的 CUDA C++ 工具链,但用 ZKP 引擎代替 GPU. 与 Nil 类似,可以使用 Risc Zero 验证 ML 模型的计算轨迹。
通用证明系统
证明系统的改进是实现 zkML 的主要推动力,特别是引入自定义门和查找表。这主要是由于 ML 对非线性的依赖。简而言之,非线性是通过激活函数(例如 ReLU、sigmoid 和 tanh)引入的,这些函数被应用于神经网络内线性变换的输出。由于数学运算门的限制,这些非线性在 zk 电路中的实现具有挑战性。位数分解和查找表可以帮助解决这个问题,将非线性的可能结果预先计算到查找表中,有趣的是在 zk 中计算效率更高。
Plonkish 证明系统往往是 zkML 最受欢迎的后端,原因就在于此。Halo2 和 Plonky2 的表格式算术方案可以通过查找参数很好地处理神经网络的非线性问题。此外,前者有一个充满活力的开发者工具生态系统,再加上灵活性,使其成为包括 EZKL 在内的许多项目的事实上的后端。
其他证明系统也有其优点。R1CS 的证明系统包括 Groth16,因为它的证明规模小;Gemini,因为它可以处理极其庞大的电路和线性时间验证器。基于 STARK 的系统,如 Winterfell 校验器/验证器库也很有用,特别是当通过 Giza 的工具实现时,它将开罗程序的轨迹作为输入,并使用 Winterfell 生成 STARK 证明以证明输出的正确性。
zkML 专精证明系统
在设计高效的证明系统方面已经取得了一些进展,该系统可以处理高级 ML 模型的复杂的、对电路不友好的操作。像 zkCNN 这样基于 GKR 证明系统的系统,或者像 Zator 这样使用组合技术的系统,往往比它们的通用对应系统更有性能,这一点在 Modulus 实验室的基准测试报告中得到证明。
zkCNN 是一种使用零知识证明 rollup 神经网络正确性的方法。它使用 sumcheck 协议来证明快速傅里叶变换和 rollup,其线性证明者时间比渐进地计算结果快。为交互式证明引入了一些改进和概括,包括验证 rollup 层、ReLU 激活函数和 max pooling. 鉴于 Modulus Labs 的基准测试报告,他们发现它在证明生成速度和 RAM 消耗方面都优于其他概括式证明系统,因此 zkCNN 特别有趣。
Zator 是一个旨在探索使用递归 SNARK 来验证深度神经网络的项目。目前验证深层模型的制约因素是将整个计算轨迹装入单个电路。Zator 建议使用递归 SNARK 一次验证一个层,它可以逐步验证 N 步重复计算。他们使用 Nova 将 N 个计算实例减少为一个单一的实例,可以以一个步骤的代价进行验证。通过这种方法,Zator 能够对一个有 512 层的网络进行 snark,这与目前大多数生产型人工智能模型的深度一样。Zator 的证明生成和验证时间对于主流用例来说仍然太大,但他们的合成技术还是很有趣。
应用
鉴于 zkML 的早期阶段,它的大部分重点是在上述基础设施上。然而,今天也有一些项目正在进行应用。
Modulus Labs 是 zkML 领域中最多样化的项目之一,既致力于实例应用,也致力于相关研究。在应用方面,Modulus Labs 已经通过 RockyBot——一个链上交易机器人——和 Leela vs. the World——一个象棋游戏,全人类与 Leela 象棋引擎的一个经过验证的链上实例对弈。该团队还涉足研究,撰写了 The Cost of Intelligence,对各种证明系统的速度和效率在不同的模型规模下进行了基准测试。
Worldcoin 正在应用 zkML,试图制定一个保护隐私的人格证明协议。世界币正在使用定制的硬件来处理高分辨率的虹膜扫描,这些扫描被插入到他们的 Semaphore 实现中。然后,这可以用来执行有用的操作,如成员证明和投票。他们目前使用带有安全飞地的可信运行环境来验证相机签名的虹膜扫描,但他们最终的目标是使用 ZKP 来证明神经网络的正确推断,以获得密码学级别的安全保证。
Giza 是一个协议,能够使用完全无信任的方法在链上部署 AI 模型。它使用的技术栈包括代表机器学习模型的 ONNX 格式,将这些模型转换为 Cairo 程序格式的 Giza Transpiler,以可验证和确定性方式执行模型的 ONNX Cairo Runtime,以及在链上部署和执行模型的 Giza Model 智能合约。虽然 Giza 也可以归入模型到证明的编译器类别,但他们作为 ML 模型的市场定位是当今更有趣的应用之一。
Gensyn 是一个用于训练 ML 模型的分布式硬件供应网络。具体来说,他们正在设计一个基于梯度下降的概率审计系统,并使用模型检查点,使去中心化的 GPU 网络能够为全尺寸模型的训练提供服务。虽然他们在这里的 zkML 应用对于他们的用例来说是非常具体的——他们想确保当一个节点下载和训练一块模型时,他们对模型的更新是诚实的——但它展示了 zk 和 ML 结合的力量。
ZKaptcha 专注于 Web3 中的机器人问题,为智能合约提供验证码服务。他们目前的实现是让终端用户通过完成验证码来产生一个人类工作的证明,这由他们的链上验证器验证,并由智能合约通过几行代码访问。今天,他们主要只依靠 zk,但他们打算在未来实现 zkML,类似于现有的 Web2 验证码服务,分析鼠标运动等行为,以确定用户是否为人类。
鉴于 zkML 市场是如此之早,很多应用已经在黑客松层面进行了实验。项目包括 AI Coliseum,这是一个使用 EZKL 构建的链上人工智能竞赛,使用 ZK 证明来验证机器学习的输出;Hunter z Hunter,这是一个使用 EZKL 库来验证图像分类模型的输出与 halo2 电路的照片寻宝游戏;zk Section 9,将人工智能图像生成模型转换成电路,用于铸造和验证 AI 艺术。
zkML 的挑战
虽然改进和优化正在以光速进行,但 zkML 领域仍然存在一些核心挑战。这些挑战从技术到实践都有,包括:
- 以最小的精度损失进行量化
- 电路尺寸,特别是当网络由许多层组成时
- 矩阵乘法的高效证明
- 对抗性攻击
量化是将大多数 ML 模型用来表示模型参数和激活的浮点数表示为定点数字的过程,这在处理 zk 电路的场计算时是必要的。量化对机器学习模型精度的影响取决于所使用的精度水平。一般来说,使用较低的精度(即较少的比特)会导致精度降低,因为它可能会引入舍入和近似错误。然而,有几种技术可以用来尽量减少量化对准确性的影响,比如在量化后对模型进行微调,以及使用量化感知训练等技术。此外,Zero Gravity——zkSummit 9 上的一个黑客松项目——表明,为边缘设备开发的替代神经网络架构,如失重神经网络,可用于避免电路内量化的问题。
在量化之外,硬件是另一个关键挑战。一旦机器学习模型通过电路正确表示,由于 zk 的简洁特性,验证其推论的证明是很便宜和快速的。这里的挑战不是在验证器上,而是在证明者上,因为随着模型大小的增长,RAM 的消耗和证明生成的时间会迅速增加。某些证明系统(例如基于 GKR 的系统,使用 sumcheck 协议和分层算术电路)或组成技术(例如用 Groth16 包装 Plonky2,它在证明时间上很有效,但在大模型的有效证明大小上很差)更适合处理这些问题,但管理权衡是在 zkML 中构建项目的核心挑战。
在对抗性方面,也仍有工作要做。首先,如果一个无信任协议或 DAO 选择实现一个模型,那么在训练阶段仍然存在对抗性攻击的风险(例如,训练一个模型在看到一个输入时表现出特定的方式,这可能被用来操纵后来的推断)。联合学习技术和训练阶段的 zkML 可能是最小化这种攻击面的一种方法。
另一个核心挑战是,当一个模型被保护隐私时,模型偷窃攻击的风险。虽然一个模型的权重可以被混淆,但从理论上讲,只要有足够的输入输出对,就有可能对权重进行反向工程。这主要是小规模模型的风险,但它仍然是一个风险。
扩展智能合约
虽然在优化这些模型以在 zk 的约束条件下运行方面存在一些挑战,但正在以指数级的速度进行改进,一些人预计,假设进一步的硬件加速,我们将很快达到与更广泛的 ML 空间的平等。为了强调这些改进的速度,zkML 已经从 2021 年 0xPARC 的 zk-MNIST 演示,显示了一个可以在可验证的电路中进行的小规模的 [MNIST](https://en.wikipedia.org/wiki/MNIST_database#:~:text=The MNIST database (Modified National,the field of machine learning.) 的图像分类模型,到 Daniel Kang 的论文在不到一年的时间里对 ImageNet 规模的模型做了同样的验证。2022 年 4 月,这个 ImageNet 规模的模型从 79% 的准确率进一步提高到 92% 的准确率,像 GPT-2 这么大的网络在近期内是潜在可行的,尽管今天的证明时间很慢。
我们认为 zkML 是一个丰富的、不断增长的生态系统,它希望扩大区块链和智能合约的能力,使其更加灵活、适应性强、智能化。
虽然 zkML 仍处于早期发展阶段,但它已经开始显示出令人鼓舞的结果。随着技术的发展和成熟,我们可以期待看到 zkML 在链上的更多创新使用案例。
免责声明:本文不构成投资建议,用户应考虑本文中的任何意见、观点或结论是否符合其特定状况,及遵守所在国家和地区的相关法律法规。



24H热门新闻
暂无内容